Hello ! Vous êtes 946 à me suivre, merci pour votre confiance !
🚀 Actualités
Ce numéro sort avec un peu de retard, et pour une bonne raison : je suis en pleine construction ! Avant de plonger dans le sujet technique du jour, voici les 3 grandes actualités et comment vous pouvez y prendre part.
1.🎓 Formation "Streamlit Unleashed" ! La formation est déjà lancée avec 12 beta-testeurs ! J'en suis à 70% de la création, les dernières vidéos arrivent ! C'est le premier cours hébergé sur ma nouvelle plateforme de formation, conçue pour vous offrir une expérience d'apprentissage simple et directe, sans fioritures. 👉 Le tarif "Early Bird" est encore disponible pour une durée limitée (26/09).Profitez-en ici avant qu'il ne disparaisse !
2.💼 Beta "Portfolio Data" : J'ai reçu énormément de demandes pour des accompagnements sur la création d'un portfolio data. Je vais lancer une bêta privée dans les semaines à venir pour un petit groupe. 👉 Intéressé(e) ? Toutes les infos ici !
3.✨ Intégration SQLMastery : Un mot pour les 145+ beta-testeurs inscrits de SQLMastery : la nouvelle plateforme accueillera à terme TOUS les contenus. L'objectif est de rassembler la théorie et la pratique au même endroit : Un cours SQL, des projets concrets et une plateforme interactive pour se tester. Fini de jongler entre plusieurs sites, la construction de cette plateforme commune avance bien !
Maintenant que vous savez tout, passons à notre sujet du jour.
L'expérience de construire ces projets m'a rappelé un point essentiel : comment s'assurer que ce qui fonctionne manuellement aujourd'hui continuera de fonctionner de manière fiable et automatique demain ? C'est tout l'enjeu de l'orchestration, et c'est ce que nous allons explorer.
Data Engineering pour Analystes : Les bases que personne n'enseigne
Aujourd'hui, on s'attaque à un sujet qui change la vie d'un analyste : l'automatisation. Mais attention, pas n'importe comment. L'idée n'est pas de vous transformer en Data Engineer, mais de vous donner les clés pour résoudre vos problèmes, avec des outils adaptés à votre réalité : celle d'analyses récurrentes, de contraintes IT fortes et d'un besoin de simplicité et d'autonomie.
Le problème que tout analyste connaît (et que les autres ignorent)
Entre l'exploration de vos données et la présentation de vos insights, il y a cette zone grise. Ce marécage de tâches répétitives que l'on traverse chaque jour, chaque semaine : récupérer les mêmes fichiers Excel, corriger les mêmes anomalies de formatage, rafraîchir les mêmes tableaux croisés dynamiques. Vous connaissez cette routine, n'est-ce pas ? Non seulement elle est une source d'erreurs humaines, mais elle nous maintient dans un rôle d'exécutant et bride notre réactivité face aux demandes du business. C'est un "coût d'opportunité" invisible : chaque heure passée à refaire la même chose est une heure qui n'est pas passée à chercher de nouveaux insights.
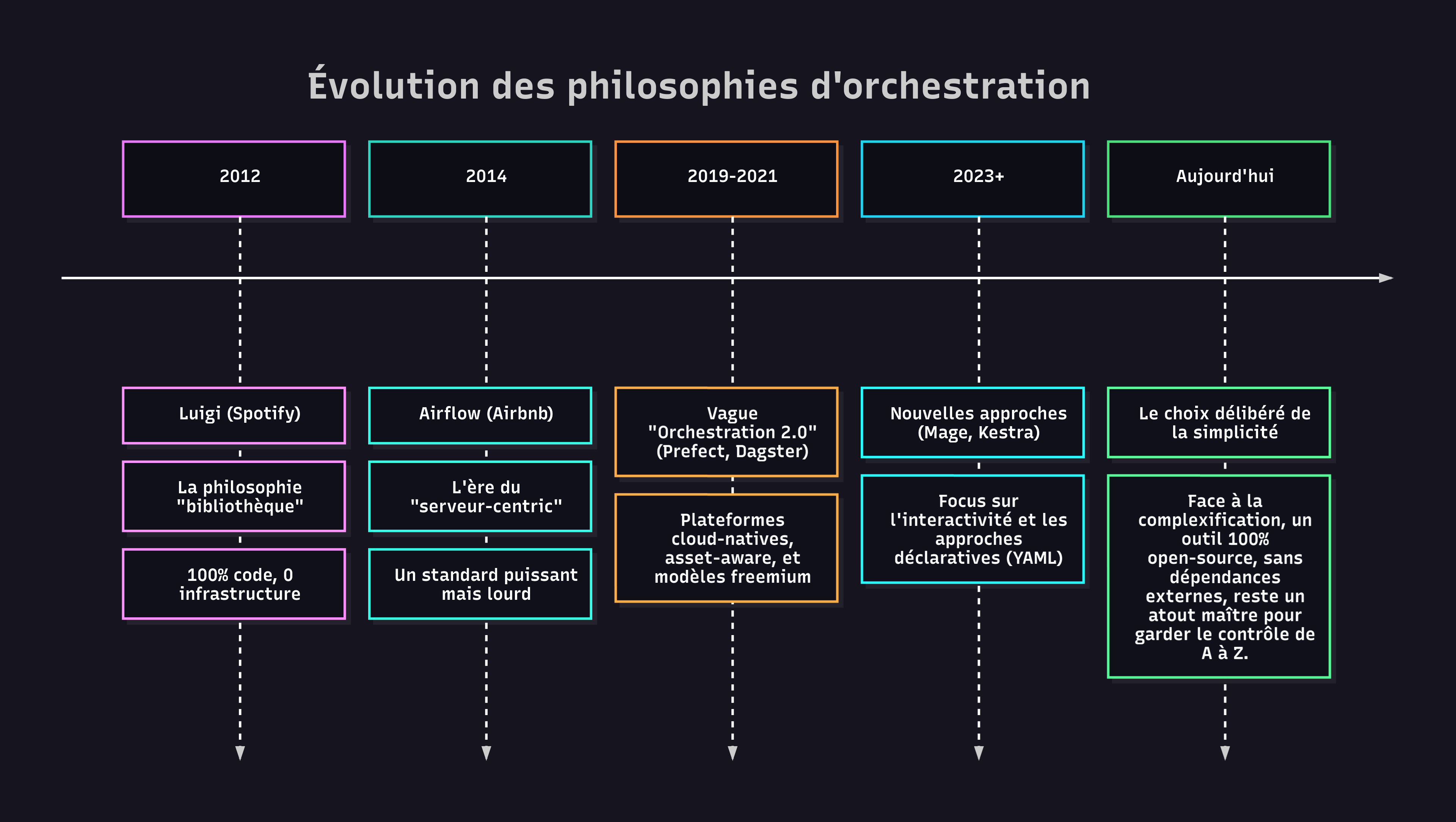
La jungle des outils : pourquoi faire simple quand on peut faire compliqué ?
Pour automatiser, il existe une multitude d'outils, les orchestrateurs. Mais leur évolution a créé deux philosophies bien distinctes. D'un côté, des plateformes ultra-puissantes, pensées pour les Data Engineers, qui exigent des serveurs, des déploiements complexes et des compétences spécifiques. De l'autre, une approche "bibliothèque" pure, conçue pour être légère, simple et entièrement sous votre contrôle.
Ce que je vous propose, ce n'est pas un comparatif universel, mais un point de vue assumé : celui de l'analyste qui cherche le chemin le plus court vers l'efficacité.
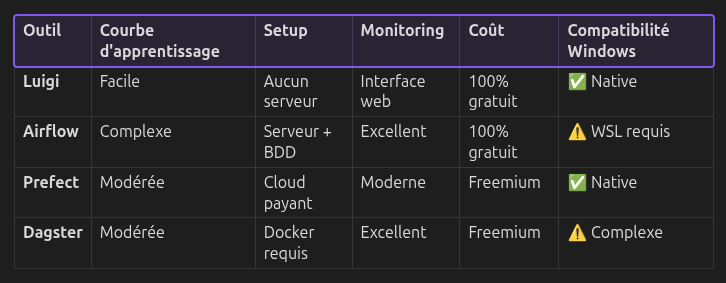
Un mot pour les Data Engineers : Oui, Airflow, Dagster et Prefect sont plus puissants. Ils gèrent des milliers de pipelines complexes, offrent une observabilité fine et des fonctionnalités avancées. Mais cette puissance a un coût (en complexité, en infrastructure, en maintenance) qui est totalement disproportionné pour un analyste cherchant à automatiser un rapport hebdomadaire. Ici, nous ne cherchons pas le meilleur outil du marché, mais le meilleur outil pour le job d'un analyste.
Le tableau suivant résume ce choix, avec nos critères en tête :
Pour un analyste en entreprise, le choix de Luigi n'est pas un compromis, c'est une décision stratégique : celle de l'autonomie et de la simplicité.
Luigi : L'orchestration pensée pour ceux qui n'ont pas le temps
Concrètement, qu'est-ce qui rend Luigi si adapté à notre quotidien ? Il a été pensé pour s'intégrer dans nos contraintes, pas pour les bouleverser :
Aucune dépendance externe : Pas de serveur, pas de base de données, pas de service cloud. Votre IT n'a rien à valider. Vous êtes 100% autonome.
Compatible Windows nativement : Pas besoin de WSL, de Docker ou de machine Linux. Vous lancez pip install luigi sur votre PC d'entreprise, et ça fonctionne. C'est le point le plus crucial pour contourner les blocages organisationnels.
Code Python pur : C'est un avantage immense. Cela veut dire que vous pouvez utiliser tout l'écosystème Python que vous connaissez déjà : pytest pour tester vos tâches, Polars pour les transformations, requests pour les APIs. Votre pipeline n'est pas une configuration YAML, c'est un programme Python, ce qui le rend infiniment plus flexible et facile à déboguer.
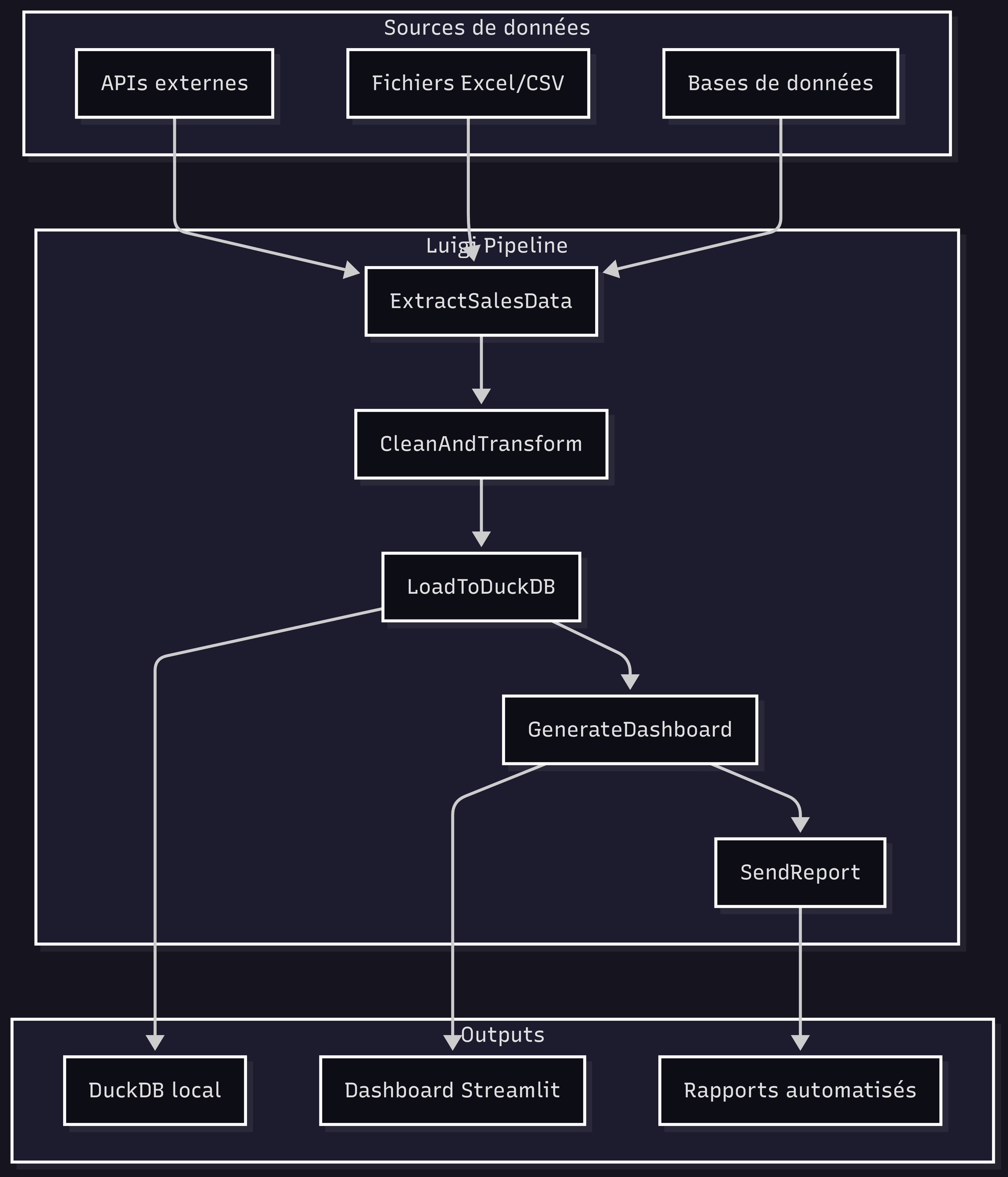
Idempotence par conception : C'est un concept clé. Chaque tâche Luigi doit produire une "cible" (un fichier, une table dans une base de données). Avant de se lancer, Luigi vérifie si cette cible existe déjà. Si oui, il considère la tâche comme réussie et passe à la suite. C'est une sécurité incroyable : si votre pipeline plante au milieu, vous pouvez le relancer, et il ne recommencera que ce qui n'a pas été fait.
Un pipeline Luigi, c'est avant tout du bon sens mis en code. Chaque tâche déclare ce dont elle a besoin pour démarrer, et Luigi se charge de les exécuter dans le bon ordre.
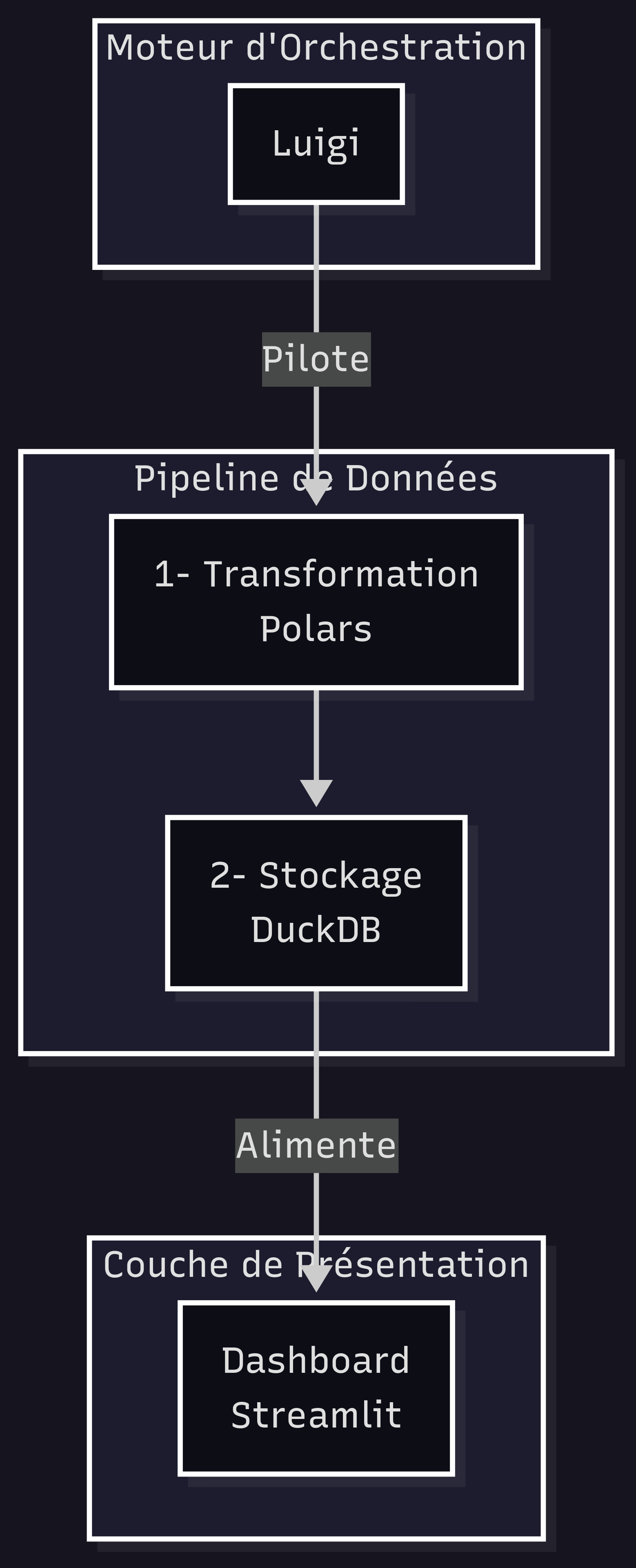
La stack de l'analyste autonome
Luigi n'est pas un outil isolé. Il est le liant, le chef d'orchestre de la stack que nous avons explorée dans les numéros précédents. Il met en musique Polars, DuckDB et Streamlit pour créer un système complet, cohérent et performant, qui tourne entièrement sur votre machine.
Votre plan d'action : démarrer petit, gagner gros
L'adoption de Luigi se fait en douceur, sans "big bang". Voici une feuille de route réaliste pour vous lancer.
Commencez par automatiser un seul rapport simple. Le gain de temps et de fiabilité sera la meilleure preuve de concept pour vous et votre équipe.
Pour aller plus loin : quelques ressources triées sur le volet
Pour vous accompagner dans votre exploration de Luigi, voici quelques pistes que je trouve particulièrement pertinentes.
Documentation Officielle de Luigi: C'est la source de vérité. Elle peut sembler un peu dense au premier abord, mais elle est exhaustive. Gardez-la dans vos favoris, notamment la section sur les Targets et les Parameters.
Des projets GitHub pour s'inspirer : Rien de tel que de lire du code. Cherchez sur GitHub des projets comme "Luigi spotify analysis" ou "Luigi web scraping pipeline". Vous y trouverez des exemples concrets de pipelines pour analyser des données d'API (comme celle de Spotify) ou pour automatiser la collecte de données sur des sites web. Observez comment les tâches sont structurées et comment les dépendances sont gérées.
La liste des contrib : Une fois que vous serez plus à l'aise, explorez ce lien. Il contient des intégrations pré-faites pour de nombreux systèmes (bases de données, cloud storage...). C'est une mine d'or pour voir comment étendre les capacités de Luigi.
L'analyste augmenté, pas le mini-ingénieur
En adoptant un outil comme Luigi, vous ne changez pas de métier. Vous l'augmentez. Vous confiez le travail de robot à un vrai robot, pour libérer votre cerveau pour les tâches à forte valeur ajoutée : l'analyse, l'interprétation, la communication. Vous passez d'exécutant à architecte de vos propres solutions analytiques.
Conclusion
Il existe des dizaines de façons d'automatiser un workflow de données. La plupart sont complexes, coûteuses et surdimensionnées pour les besoins réels d'un data analyst. Luigi représente une autre voie : celle de la simplicité radicale, de l'autonomie et du pragmatisme. C'est l'outil parfait pour transformer vos analyses manuelles en pipelines robustes, sans demander la permission et sans dépendre de personne.
L'orchestration ne remplace pas votre expertise, elle l'amplifie. Commencez dès aujourd'hui.
À bientôt pour le prochain numéro !
Gaël
Thanks for reading DataGyver! Subscribe for free to receive new posts and support my work.