
DataGyver #13 : Claude Code pour data analysts
10 tips pour arrêter de cramer tes tokens et tenir tes sessions jusqu'au bout

Hello !
Je profite du weekend prolongé pour te partager quelques tips qui vont changer ta façon d’utiliser Claude Code. Comme tu as pu le lire dans l’actu, l’IA open bar, c’est terminé. Les limites de tokens se resserrent, les quotas tombent plus vite qu’avant. Il faut maintenant apprendre à optimiser ses ressources pour ne pas se retrouver bloqué dès le lundi soir.
Bonne nouvelle : GitHub regorge de projets open-source qui répondent exactement à ce problème. C’est ce qu’on va explorer ensemble aujourd’hui.
Avant d’aller plus loin, une actualité :
Je lance un accompagnement en cohorte de 6 semaines pour construire et déployer ton propre data product en Python, sans licence, sans dépendance IT. Je cherche encore 3 candidats motivés pour cette première cohorte. → Candidater ici, je te propose un call de 30 min pour voir si c’est fait pour toi

L’illusion du vibe coding
Il y a quelques semaines, un analyste me partage sa nouvelle routine. Il a adopté Claude Code. Ça génère du code Polars propre, les scripts tournent, il est satisfait. “C’est comme avoir un junior qui code vite”, dit-il.
Sauf qu’il utilise Claude Code comme un générateur de code amélioré. Nouvelle session à chaque fois, aucune configuration, aucun contexte persistant. Résultat : il ré-explique ses conventions à chaque session, les outputs verbeux des commandes duckdb remplissent son contexte, et les sessions deviennent de moins en moins cohérentes au fil du temps.
Ce n’est pas un problème de compétence. C’est un problème d’architecture.
Une session Claude Code de 2 heures implique environ 60 commandes CLI. Sans configuration, ces outputs représentent 210 000 tokens, de quoi remplir une fenêtre de 200k tokens rien qu’avec du bruit terminal. L’agent perd le fil, la qualité baisse, les sessions se raccourcissent. Et l’analyste pense que Claude Code n’est pas fait pour lui.
Cette newsletter, c’est les 10 configurations et outils qui changent l’équation. Pas de tips génériques. Des techniques vérifiées, pour un workflow de data analyst.
Tip 1 : CLAUDE.md + .claudeignore — poser les fondations avant la première session
CLAUDE.md n’est pas un README amélioré. C’est la mémoire statique de ton agent : tes conventions de nommage, tes règles métier, les contraintes de ta stack. Sans ça, tu ré-expliques à chaque session que tu utilises Polars et non pandas, uv et non pip, que ta table de faits s’appelle fact_ventes et non sales.
Un CLAUDE.md efficace pour un DA contient trois choses : les conventions de code (stack, style, structure), les contraintes métier (règles de calcul des KPIs, périmètre des données), et les pointeurs vers les fichiers de référence. Sous 500 lignes. Au-delà, le signal se noie dans le bruit.
Une règle simple :
Un CLAUDE.md efficace suit une règle simple : pour chaque ligne, pose-toi la question "est-ce que supprimer ça ferait faire des erreurs à Claude ?" Si non, coupe. Un fichier trop long ne fait pas ignorer les mauvaises règles, il fait ignorer toutes les règles.
Le complément immédiat : .claudeignore. C’est le .gitignore de Claude. Sans lui, l’agent tente de lire tes fichiers Parquet, tes exports CSV de 500 Mo, tes dossiers data/raw/. Il ne peut pas les lire utilement, mais il essaie quand même et consomme du contexte.
# .claudeignore
data/raw/
data/interim/
*.parquet
*.csv
*.xlsx
outputs/Gain immédiat et gratuit : 20 à 40% de baseline de contexte récupéré.
Tip 2 : Le schéma de ta base dans CLAUDE.md
L’erreur la plus fréquente en pratique : demander une requête DuckDB à un agent qui ne connaît pas tes tables. Il génère une requête plausible avec des noms de colonnes inventés. Tu corriges. Il regénère. Trois allers-retours pour un résultat qu’il aurait obtenu du premier coup.
La solution est triviale : coller le DDL dans CLAUDE.md. Pas tout le schéma si ta base est large, mais les tables principales avec leurs types et les jointures clés.
-- CLAUDE.md, section Schéma
-- Table principale des ventes
CREATE TABLE fact_ventes (
id_vente INTEGER,
date_vente DATE,
id_client INTEGER,
id_produit INTEGER,
montant DECIMAL(10,2),
region VARCHAR(50)
);
-- Jointure : fact_ventes.id_produit = dim_produit.id_produitL’agent connaît les types, les noms exacts, les relations. Zéro erreur de nommage, zéro aller-retour de correction.
Tip 3 : Les Skills — forcer les conventions de ta stack à chaque session
Un Skill est un fichier Markdown stocké dans ~/.claude/skills/. L’agent le charge avant de générer du code. Ce qu’il encode : tes conventions de stack, tes patterns architecturaux, tes règles de qualité.
Le résultat concret : peu importe ce que tu demandes, l’agent génère du Polars (jamais pandas), utilise uv (jamais pip), crée des fichiers dans src/ avec la structure de la newsletter #1. La cohérence entre tes projets n’est plus une discipline personnelle que tu dois rappeler à chaque session. C’est une contrainte systémique.
# ~/.claude/skills/data-stack.md
## Stack obligatoire
- Toujours Polars, jamais pandas
- Toujours uv pour la gestion des dépendances
- Structure src/ avec pyproject.toml
- Tests avec pytest, types hints partout
- DuckDB pour les requêtes analytiques SQLLes Skills se chaînent : /skill data-stack puis /skill polars-patterns avant de démarrer une session.
Tip 4 : CLI plutôt que MCP — le choix contre-intuitif
Les benchmarks 2026 sont documentés et sourcés. Comparaison gh CLI vs GitHub MCP : 4 à 32 fois moins de tokens consommés, avec une fiabilité mesurée à 100% contre 72% pour le MCP. La raison est structurelle : les schémas MCP se chargent entièrement à chaque session, même si tu n’utilises pas le tool de la journée. Le GitHub MCP complet, c’est 55 000 tokens de définitions qui entrent en contexte au démarrage.
gh, duckdb, docker, uv : ces outils sont dans les données d’entraînement de Claude depuis des années. Il les maîtrise nativement, sans schéma à charger. Les commandes sont composables via les pipes Unix, compressables par RTK (tip 5), et zéro coût fixe de connexion.
La règle pratique : utiliser un MCP uniquement quand il n’existe pas de CLI viable. Notion (pas de CLI), auth OAuth multi-utilisateurs. Pour tout le reste : CLI.
Note technique à connaître : depuis avril 2026, Claude Code active le Tool Search par défaut (lazy loading des schémas MCP). Les définitions complètes n’entrent en contexte que si tu appelles effectivement le tool. Ça réduit l’impact des MCP dormants. Le coût des appels réels, lui, reste identique.
Tip 5 : RTK — comprimer les outputs CLI avant qu’ils mangent ton contexte
RTK (Rust Token Killer) est un proxy CLI open-source qui s’intercale entre Claude et le terminal. Il intercepte les commandes Bash et comprime les outputs avant qu’ils atteignent le contexte.
Le mécanisme est transparent : le hook PreToolUse réécrit git status en rtk git status avant exécution. Claude ne voit jamais la réécriture. Il reçoit directement l’output compressé.
Ce que RTK fait concrètement : il filtre le bruit, groupe les outputs reliés, tronque les redondances, déduplique les lignes répétées.
Benchmarks officiels mesurés sur les commandes les plus fréquentes :

Pour un DA, les gains les plus immédiats arrivent sur les sessions avec beaucoup de git, de duckdb CLI, de pytest. L’impact est minimal sur des sessions de lecture et d’édition de fichiers (les tools Read, Grep, Glob de Claude Code bypassent le hook RTK).
# Installation
curl -fsSL https://install.rtk-ai.app | sh
rtk init -g # installe le hook dans Claude Code + RTK.md
# Vérifier les économies réelles
rtk gain # cumul toutes sessions
rtk gain --history # détail par commandeUne fois installé, zéro changement de workflow.
Tip 6 : context-mode — sandbox pour tes gros outputs data
C’est le tip le plus impactant pour un data analyst, et le moins connu.
Le problème : quand tu analyses un fichier CSV de 500 lignes avec Claude Code, le fichier chargé + son output entrent en contexte. Pour un analyste qui travaille sur de gros volumes, le contexte explose rapidement.
context-mode est un MCP server qui sandboxe les outputs lourds dans une base SQLite locale et ne remonte au contexte qu’un résumé structuré. Les données brutes ne quittent jamais ta machine.
Benchmark mesuré sur des cas data réels :

Sur une session complète : 315 KB d’output brut compressé à 5,4 KB. Ce qui était une session de 30 minutes avant d’atteindre les limites devient une session de 3 heures.
# Installation via plugin Claude Code
/plugin marketplace add mksglu/context-mode
/plugin install context-mode@context-modecontext-mode ajoute aussi une continuité de session : chaque décision, chaque erreur rencontrée, chaque modification de fichier est indexée dans SQLite avec BM25. Quand le contexte compacte, l’état est restauré à partir des événements pertinents. L’agent reprend là où il s’était arrêté.
Tip 7 : Caveman — forcer la concision pour les longues sessions
Celui-ci, je peux en parler en direct : j’utilise Caveman en mode lite depuis quelques semaines. L’effet est immédiat.
Caveman est un skill/plugin qui force Claude à répondre sans préambule rhétorique, sans formules de politesse, sans justifications inutiles. “I’d be happy to help you with that” (8 tokens gaspillés), “The reason this is happening is because” (7 tokens), “I would recommend that you consider” (7 tokens) : tout ça disparaît. Le code reste intact, les messages d’erreur aussi, les termes techniques aussi.
Benchmarks mesurés via l’API Claude sur 6 tâches techniques réelles :
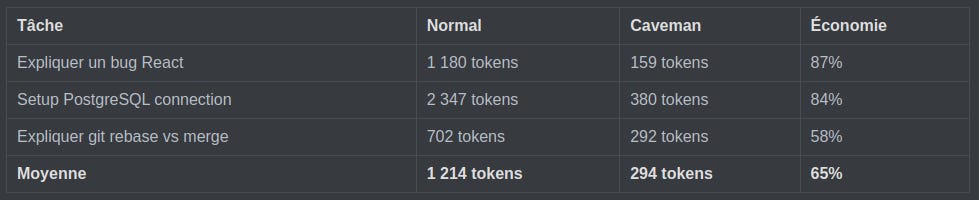
Ce qui rend Caveman défendable au-delà du gain en tokens : un paper de mars 2026 (arXiv:2604.00025) a montré que contraindre les grands modèles à des réponses brèves améliorait la précision de 26 points de pourcentage sur certains benchmarks. Caveman ne rend pas le raisonnement plus pauvre. Il rend la présentation plus dense.
# Installation
claude plugin marketplace add JuliusBrussee/caveman
claude plugin install caveman@caveman
# Activation dans une session
/caveman # active
# stop caveman # désactiveÀ utiliser sur les sessions longues avec des tâches bien définies. À désactiver quand tu explores une architecture ou que tu veux le raisonnement complet d’Opus.
Tip 8 : Hooks PreToolUse/PostToolUse — automatiser la qualité sans y penser
Les hooks sont des scripts que Claude Code exécute avant ou après chaque action de l’agent. Deux usages directs pour un DA.
PreToolUse : bloquer les actions risquées avant qu’elles s’exécutent. Exemple concret : un hook qui détecte toute écriture en base hors environnement de dev et bloque l’opération. L’agent ne peut pas accidentellement modifier ta prod, même si tu lui demandes sans faire attention au contexte actif.
{
"PreToolUse": [{
"matcher": "tool == \"Bash\" && tool_input.command matches \"(INSERT|UPDATE|DELETE|DROP)\"",
"hooks": [{
"type": "command",
"command": "if [ \"$ENV\" != \"dev\" ]; then echo '[Hook] Écriture bloquée hors env dev' >&2; exit 1; fi"
}]
}]
}PostToolUse : lancer automatiquement les tests après chaque modification de fichier Python. L’agent modifie src/pipeline.py, pytest se lance, les erreurs remontent dans le contexte. Claude les voit et corrige sans que tu aies à dire quoi que ce soit.
Le principe derrière ces deux hooks : tu industrialises la qualité au niveau de l’architecture, pas de la vigilance personnelle.
Tip 9 : MAX_THINKING_TOKENS=10000 + subagent code-reviewer
Deux configurations, différents niveaux d’investissement.
La plus rapide : MAX_THINKING_TOKENS. Par défaut à 31 999, c’est le budget de thinking caché que Claude consomme à chaque réponse, invisible dans l’interface. Le passer à 10 000, c’est 70% de réduction sur ce coût invisible, sans dégradation perceptible sur les tâches de coding courantes.
{
"env": {
"MAX_THINKING_TOKENS": "10000",
"CLAUDE_AUTOCOMPACT_PCT_OVERRIDE": "50",
"CLAUDE_CODE_SUBAGENT_MODEL": "haiku"
}
}CLAUDE_AUTOCOMPACT_PCT_OVERRIDE à 50 : compacte à mi-contexte au lieu d’attendre les 95%. Les sessions restent cohérentes plus longtemps. CLAUDE_CODE_SUBAGENT_MODEL à haiku : les sous-agents simples (recherche de fichiers, grep, tâches mécaniques) tournent sur Haiku. L’économie est substantielle sur les sessions qui délèguent beaucoup.
Le niveau suivant : créer un subagent code-reviewer dédié. Fichier ~/.claude/agents/code-reviewer.md avec les conventions de ta stack. Tu l’appelles en fin de session avec /code-review. Il ne “relit” pas le code vaguement. Il vérifie contre un référentiel précis : types Polars corrects, structure src/, conventions de commit, imports manquants. Il produit un rapport structuré, pas un avis général.
Tip 10 : /compact stratégique — ne pas compacter n’importe quand
La compaction automatique de Claude Code se déclenche à 95% du contexte. Le problème : ce seuil est arbitraire. Il peut tomber en pleine implémentation, au milieu d’un refactoring qui s’étale sur plusieurs fichiers. Tu perds les noms de variables locaux, les chemins exacts des fichiers en cours de modification, l’état partiel de la tâche.
CLAUDE_AUTOCOMPACT_PCT_OVERRIDE=50 (vu au tip 9) règle une partie du problème en compactant plus tôt. Mais l’essentiel est de savoir quand compacter manuellement avec /compact.
Bons moments : après l’exploration et avant l’implémentation, après avoir complété un milestone, après un débug réussi avant de reprendre le développement. Mauvais moment : en pleine feature qui touche 4 fichiers.
/compact Focus on the DuckDB pipeline structure and Polars transformationsL’instruction après /compact guide ce que Claude préserve dans le résumé. Sans instruction, la compaction est générique. Avec, elle préserve le contexte métier pertinent pour la suite de la session.
Le complément utile : /rename avant /clear. Nommer une session avant de la fermer te permet de la retrouver avec /resume.
Ce qu’on construit ensemble en 6 semaines
Ces 10 tips ont un point commun : ils supposent une architecture préalable. CLAUDE.md, Skills, hooks, subagents, context-mode ne s’improvisent pas session par session. Il faut les configurer une fois, proprement, sur ton cas d’usage.
C’est exactement ce que l’accompagnement que je Iance te permet de construire en 6 semaines.
Semaine 1-2 : installation de Claude Code, configuration du set de Skills fourni pour la stack DuckDB/Polars/Streamlit, construction du CLAUDE.md de ton projet en live, premiers pipelines générés par l’agent.
Semaine 3-4 : dashboard Streamlit avec les hooks de qualité configurés, subagents spécialisés pour ton cas d’usage, automatisation du reporting.
Semaine 5-6 : déploiement Docker, CI/CD via gh CLI, ton app en production.
Tu arrives avec un cas d’usage bloqué sur tes outils actuels. Tu repars avec un data product en prod et l’architecture qui te permet de le maintenir et de l’étendre seul.
Format Done-With-You : 1h30 de live par semaine, code review asynchrone, 2 appels 1:1 → Réserver un appel de diagnostic gratuit (30 min)
Questions fréquentes
Claude Code, c’est fait pour les devs, non ? C’est ce que beaucoup d’analystes pensent au départ. Claude Code n’exige pas d’écrire du Python de mémoire. Il exige de savoir lire, valider et déployer du code. C’est une posture différente de “développeur”, pas une compétence de moins.
Combien ça coûte d’utiliser Claude Code au quotidien ? L’abonnement Claude Pro à 15€HT/mois est suffisant pour un usage de data analyst standard. Claude Max à 90€HT/mois pour les sessions très intensives.
Si Claude Code disparaît demain, qu’est-ce qui reste ? Tout. Le code produit est du Python standard, versionné sur Git, qui tourne sans Claude Code. Le CLAUDE.md, les hooks : des fichiers Markdown et des scripts bash que tu peux ouvrir dans n’importe quel éditeur. Les Skills, c’est encore plus intéressant. Le format SKILL.md est portable : le même fichier fonctionne sur Claude Code, Gemini CLI, Cursor, OpenCode et une vingtaine d’autres agents. Les Skills que tu construis dans le bootcamp ne sont pas liés à Anthropic. Si dans 6 mois Gemini CLI est meilleur sur ta stack, tu migres avec ton workflow intact. Certains développeurs configurent déjà Gemini CLI pour lire leurs fichiers CLAUDE.md, les deux outils partageant le même contexte projet. Claude Code est un outil de travail, pas une dépendance d’exécution.
RTK est-il sécurisé ? Il touche à mes commandes terminal. RTK est open-source (MIT), il ne capte aucune donnée, ne contacte aucun serveur externe. Il comprime localement les outputs avant qu’ils atteignent le contexte. Tu peux lire le code source sur github.com/rtk-ai/rtk.
Ressources
Configuration :
Outils mentionnés :
RTK : github.com/rtk-ai/rtk
context-mode : github.com/mksglu/context-mode
Caveman : github.com/JuliusBrussee/caveman
Recherche :
“Brevity Constraints Reverse Performance Hierarchies” : arXiv:2604.00025
Et toi, tu utilises déjà Claude Code ? Qu’est-ce qui coince dans ton workflow actuel ? Réponds à cet email, je lis tout.
À bientôt,
Gaël
P.S. Si tu connais un analyste qui cherche à adopter Claude Code sans perdre du temps en configuration, transfère-lui cette newsletter :)
Merci beaucoup pour cet article. Pile ce qu’il me fallait pour mieux structurer mes projets
Merci beaucoup pour cet article.
Un point à aborder quand on travaille sur les données d'entreprise : la sécurité , notamment la confidentialité et le fait que l'éditeur n'utilise pas nos données pour l'apprentissage de ses modèles. Pour Claude, les abonnements payants persos n'apportent pas cette garantie à ma connaissance. Uniquement les contrats d'entreprise ou via des tiers comme aws bedrocks.